Se você é do time antenado em tecnologia e gosta das novidades em inteligência artificial, já deve ter ouvido falar no termo “aprendizado federado”. Mas, se você nunca ouviu falar ou quer aprender mais um pouco, esse material é para você ler.
O aprendizado federado nada mais é do que um modelo alternativo pensado para melhorar os algoritmos que dominam vários aspectos da vida humana. Você já se deparou pesquisando sobre um tema e foi “bombardeado” de sugestões sobre isso em suas redes sociais, por exemplo? Pois bem, sob o sistema mais tradicional, os dados das pessoas são enviados para um servidor central onde são analisados e as informações relevantes são usadas para alterar o algoritmo. Ou seja, o aprendizado federado possibilita que os algoritmos de Inteligência Artificial adquiram experiência a partir de vários dados localizados em lugares diferentes.
De acordo com Cleilton Lima Rocha, Data Scientist (Cientista de Dados), com essa abordagem, diversas organizações já podem colaborar no desenvolvimento de modelos sem precisar compartilhar dados confidenciais diretamente entre si. “O aprendizado federado oferece uma solução que aprimora a privacidade do usuário porque os dados pessoais permanecem no dispositivo do usuário. Os algoritmos são aprimorados diretamente nos dispositivos do usuário e apenas enviam de volta configurações do modelo que possam melhorar um modelo geral e compartilhado, em vez dos dados como um todo. Isso permite que as empresas aprimorem seus algoritmos sem precisar coletar todos os dados de um usuário, fornecendo uma solução focada na privacidade”, explica Cleiton.
Nos últimos anos, conforme Cleilton, houve um avanço significativo na utilização da Inteligência Artificial, Aprendizagem de Máquina e Ciência dos Dados em aplicações corporativas. Para exemplificar, o cientista de dados lista: as instituições financeiras têm adotado modelos de aprendizagem de máquina para prevenir fraudes em transações e calcular o risco de pagamentos; os e-commerces têm desenvolvido sistemas de recomendação para alavancar o cross-selling e up-selling, e assim aumentar o lucro. “Esses são exemplos de aplicações que se beneficiam do volume de dados que as instituições possuem de seus clientes”, esclarece Cleilton.
Desenvolvimento de soluções inteligentes
O ecossistema de frameworks, bibliotecas, modelos de programação e plataformas em Big Data, elevou o potencial de desenvolvimento de soluções inteligentes e, dentre eles, o princípio da localidade, que é realizar o processamento e execução do código onde estão os dados. “Assim, como o processamento do código se moveu para onde os dados estão em um cluster – termo em inglês utilizado para fazer referência à arquitetura de sistema que une dois ou mais computadores como se fossem apenas um-, esse mesmo movimento está acontecendo para os modelos inteligentes se moverem para onde os dados estão, ou seja, serem treinados e executados diretamente nos dispositivos, principalmente quando a privacidade dos dados é essencial e enfatizada na solução”, explica o Cientista de Dados.
Privacidade dos dados
A política sobre a privacidade e a ética dos dados têm sido discutida pelos governos mundiais. Leis foram criadas para garantir os direitos dos proprietários dos dados e limitar e definir obrigações das instituições que exploram o valor existente nos dados. A GPDR (Regulamento Geral sobre Privacidade de Dados) que vigora na União Europeia (UE) e a LGPD (Lei Geral de Proteção de Dados) que está sendo implantada no Brasil, são algumas das leis existentes.
Quando pensamos em ética em torno da privacidade, compartilhamento e tomada de decisões sobre os dados, nos deparamos com alguns questionamentos: “Quem possui os dados?”; “Como valorizamos diferentes aspectos da privacidade?”; “Como obter o consentimento informado?”; dentre outros. Essas questões devem ser refletidas, especialmente, nas soluções inteligentes cuja abordagem é centralizada.
Aprendizado centralizado x aprendizado federado
O método tradicional, como a aprendizagem centralizada da máquina, possui um risco elevado à proteção de dados, devido a necessidade de manter os dados ao alcance do modelo de aprendizagem. Além disso, existe um custo associado à manutenção dos dados na nuvem ou na infraestrutura core que, obrigatoriamente, exigirá maior demanda gerencial da segurança dos ativos de dados, consumirá mais recursos computacionais e também recursos energéticos. Nesse método, segundo Cleilton, os modelos inteligentes têm acesso a todos os dados disponíveis e podem ser desenvolvidos, treinados, avaliados e evoluídos de forma totalmente centralizada.
Como desvantagem, a abordagem centralizada possui uma alta latência dos dados, pois geralmente os dados necessários para treinamento dos modelos e para as predições, classificações e/ou recomendações são enviados e processados pelos modelos que estão persistidos na nuvem. “Se o modelo estivesse no dispositivo e se beneficiasse diretamente dos dados do usuário, enviando para nuvem apenas as informações extremamente necessárias, teríamos um modelo inteligente personalizado com alta performance, melhorando, inclusive, a experiência do usuário na interação com a aplicação”, esclarece o Cientista de Dados.
Essas foram algumas das motivações para o surgimento do Aprendizado Federado (Federated Learning), cuja abordagem constrói um algoritmo de aprendizagem de máquina mantendo os dados ao nível do dispositivo. Dessa forma, é possível que, cada dispositivo, possua os seus próprios dados privados e locais e, também, forneça uma solução de aprendizagem generalizada, bem como um aprendizado personalizado com dados flexíveis e gerenciados em tempo real.
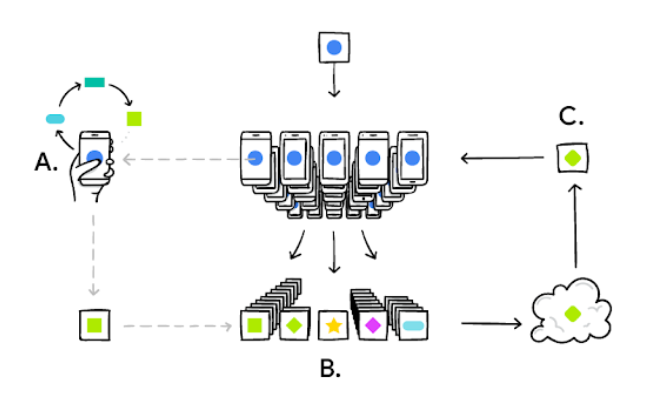
O dispositivo geral é personalizado localmente, com base na interação e dados do usuário (A). Múltiplas atualizações de usuários são agregadas (B) para formar uma consenso geral acerca das mudanças provocadas (C) no modelo geral que será novamente compartilhado. Este processo é repetido ciclicamente.

Tipos de Aprendizado Federado
Os dois principais tipos de Aprendizado Federado são: horizontal e vertical. Mas, também, há o Aprendizado por Transferência Federada. As principais diferenças são:
Aprendizado Federado Horizontal: o conjunto de variáveis (atributos dos dados) são os mesmos para todos os usuários, ou seja, o processo funciona através da introdução de conjuntos de dados similares nos dispositivos em espaços comparáveis.
Exemplo: uma instituição financeira deseja prever o risco de uma transação ser fraudulenta antes de executá-la de acordo com a interação do usuário com o aplicativo. Nesse contexto, um cliente da instituição X, possui exatamente o mesmo conjunto de atributos (por exemplo, tipo e limite da conta, valor, dia, horário, tipo da transação e etc), mas valores diferentes de um outro cliente Y, mas cada cliente teria seu modelo personalizado e seria executado no dispositivo.
Aprendizado Federado Vertical: há mais de uma fonte de dados com um conjunto de variáveis distintas para cada fonte, porém, apenas as amostras existentes nas fontes de dados são utilizadas no treinamento do modelo. Este tipo de aprendizagem seria aplicável no cenário, onde duas instituições financeiras A (um banco digital) e B (uma emissora de cartão de crédito) poderiam compartilhar o conhecimento e criar uma solução colaborativa de predição e prevenção à fraudes, embora com uma estrutura de atributos distintas e sem compartilhar os dados dos seus clientes. Um outro exemplo, seria ter um modelo inteligente de cálculo de risco de óbito dos pacientes considerando os dados existentes nas diversas fontes de dados do SUS (Sistema Único de Saúde Brasileiro), e os dados dos mesmos pacientes em uma rede de planos de saúde. As duas instituições compartilhariam o conhecimento existente nos dados, mas não os dados e informações sensíveis dos pacientes.
O Aprendizado Federado pode ser utilizado em diversos segmentos, como: saúde, financeiro, agricultura, e-commerce, dentre outros, já que, tais aplicações são extensas e incentivadas, principalmente, em soluções cuja privacidade dos dados é algo extremamente sensível, cuja computação aconteça na borda (Edge Computing), tais como dispositivos IoT, smartphones, dispositivos móveis ou sistemas inteligentes embarcados. “Com o aumento de dispositivos na borda incentivados pelo movimento de mover a computação da nuvem para Borda, (Cloud to Edge), veremos, cada vez mais, soluções de Inteligência Artificial na Borda (Edge AI), que adotam o Aprendizado Federado em seus desenvolvimentos”, afirma Cleilton.
